01S
Fastest benchmark repo to 1k starsQwen model cardHY-3 cited
1.1k GitHub stars86 tasks11 domains7,308 trajectories
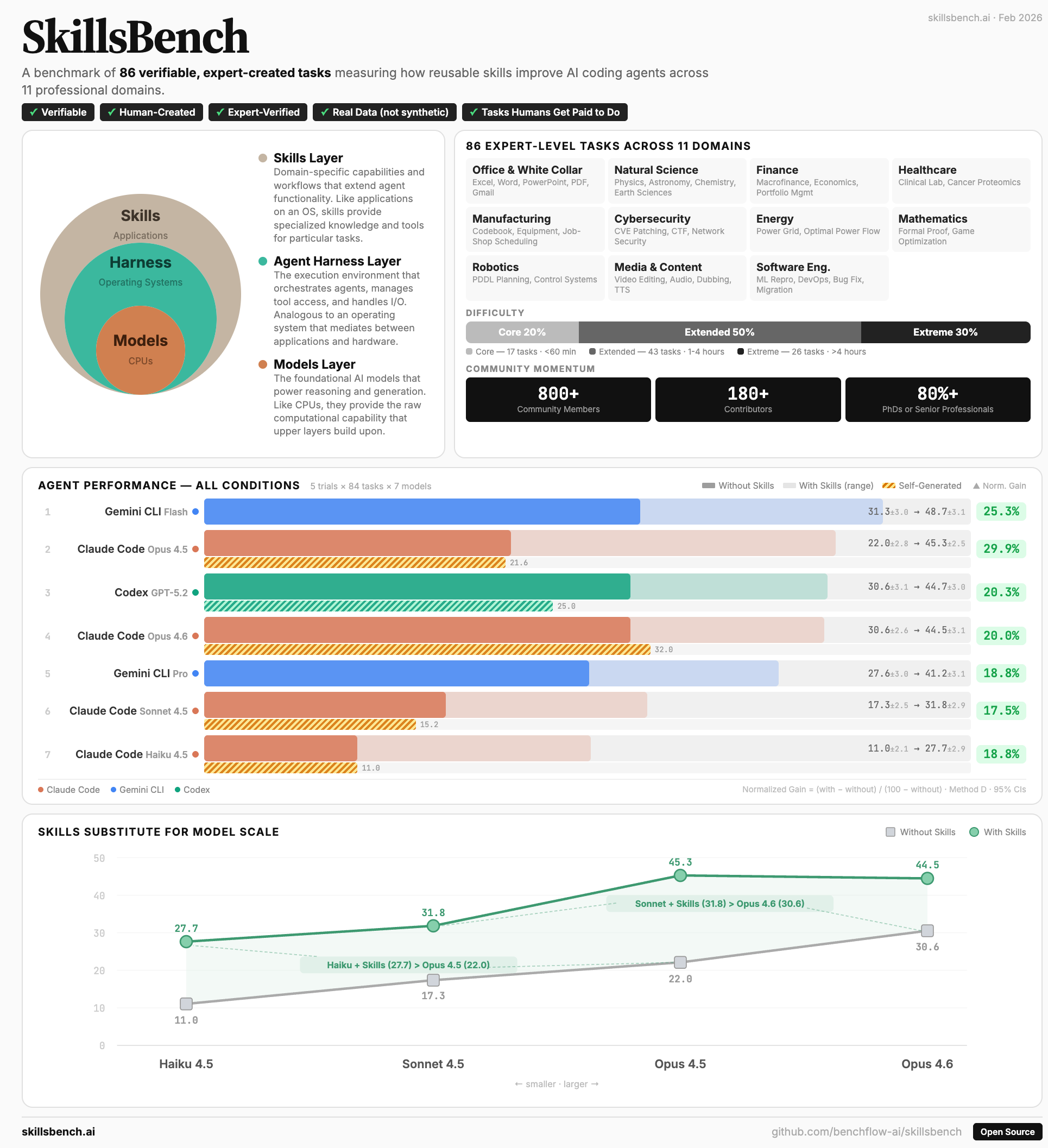
SkillsBench evaluates whether agent skills actually work. It separates skill quality from the agent’s ability to discover, compose, and apply the right skill under realistic task pressure.
- Built with 105 domain experts from Stanford, CMU, Berkeley, Oxford, Amazon, ByteDance, and more.
- Released with 40 indexed benchmarks, while the internal tracker covers 60+ benchmark sources.
- Appears in recent model cards and agent-skill research from leading labs.
Agent evaluation · skill use · benchmark design
02H
Terminal-Bench harnessRL-ready rolloutsContainerized evals
1.8k GitHub stars993 forks914 commits9 releases
Harbor is a framework for running agent evaluations, creating task environments, and generating rollouts for RL-oriented optimization. It turns benchmarks into repeatable infrastructure for agent training and analysis.
- Runs agents through reproducible containerized environments and evaluation configs.
- Supports benchmark adapters, task registries, and large-scale parallel execution.
- Produces trajectories that can be inspected, audited, and reused for optimization.
Agent infrastructure · RL environments · rollouts