My recent work focuses on LLM agents that can reason over multi-step tasks, use tools, interact with task environments, and improve through evaluation, data feedback, and reinforcement learning.
ByteDanceLLM algorithms
Alibaba ATHInternmultimodal LLMs
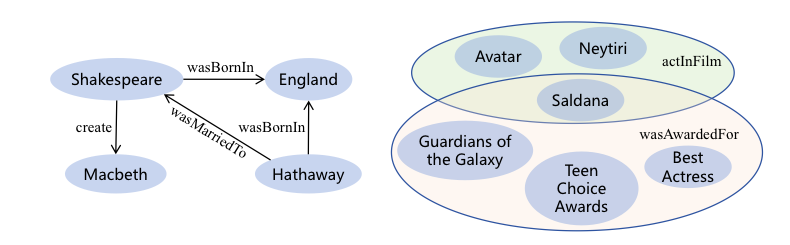
Tencent ARCInterndocument AI
News
Recent Signals
Live
✦
SkillsBench became the fastest benchmark repository to reach 1k GitHub stars, with 1.1k stars within two months of release
✧
SkillsBench appeared in recent model-card and release discussions, including Qwen 3.6 Plus and HY-3
◌
SkillsBench now covers 86 tasks, 11 domains, 7,308 trajectories, and 40 indexed benchmarks
↗
Harbor v0.6.5 was released for agent evaluation, task environments, and RL-ready rollout workflows
A benchmark for evaluating whether agent skills actually work across diverse tasks, separating skill quality from an agent’s ability to discover and use the right skill.
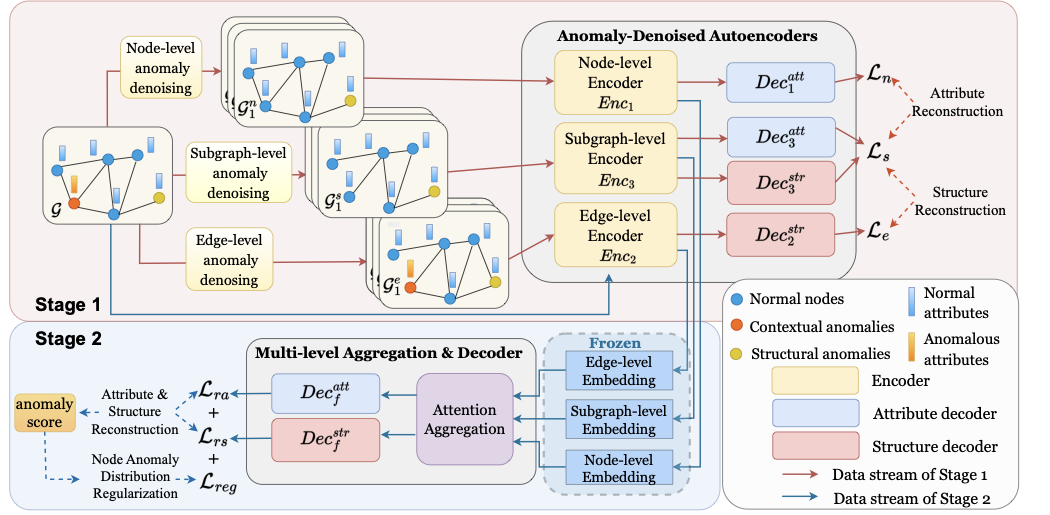
A two-stage graph anomaly detection framework that pretrains graph autoencoders on anomaly-denoised graphs at node, edge, and subgraph levels, then retrains the decoder on the original graph to mitigate anomaly overfitting and homophily traps.
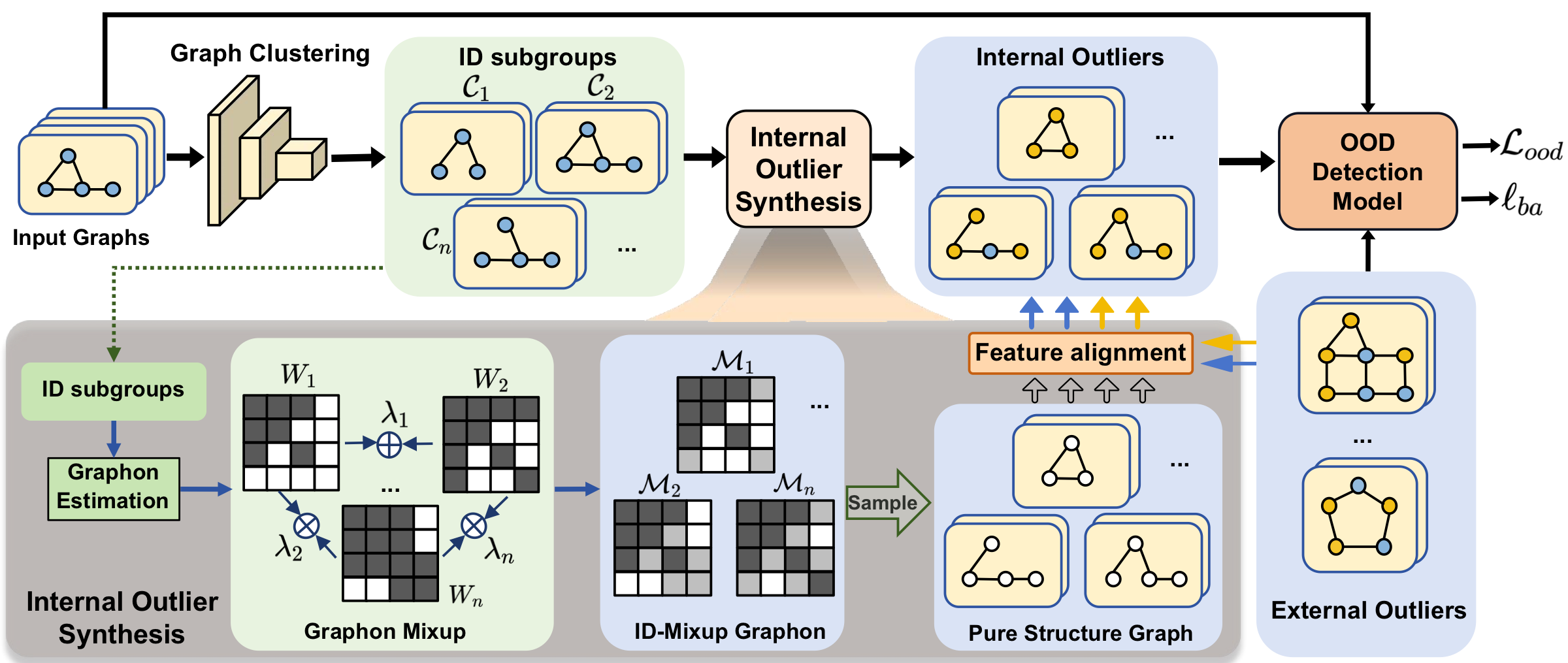
Studies graph out-of-distribution detection with hybrid synthetic and internal outlier exposure, improving robustness when abnormal patterns are scarce or shift across graphs.



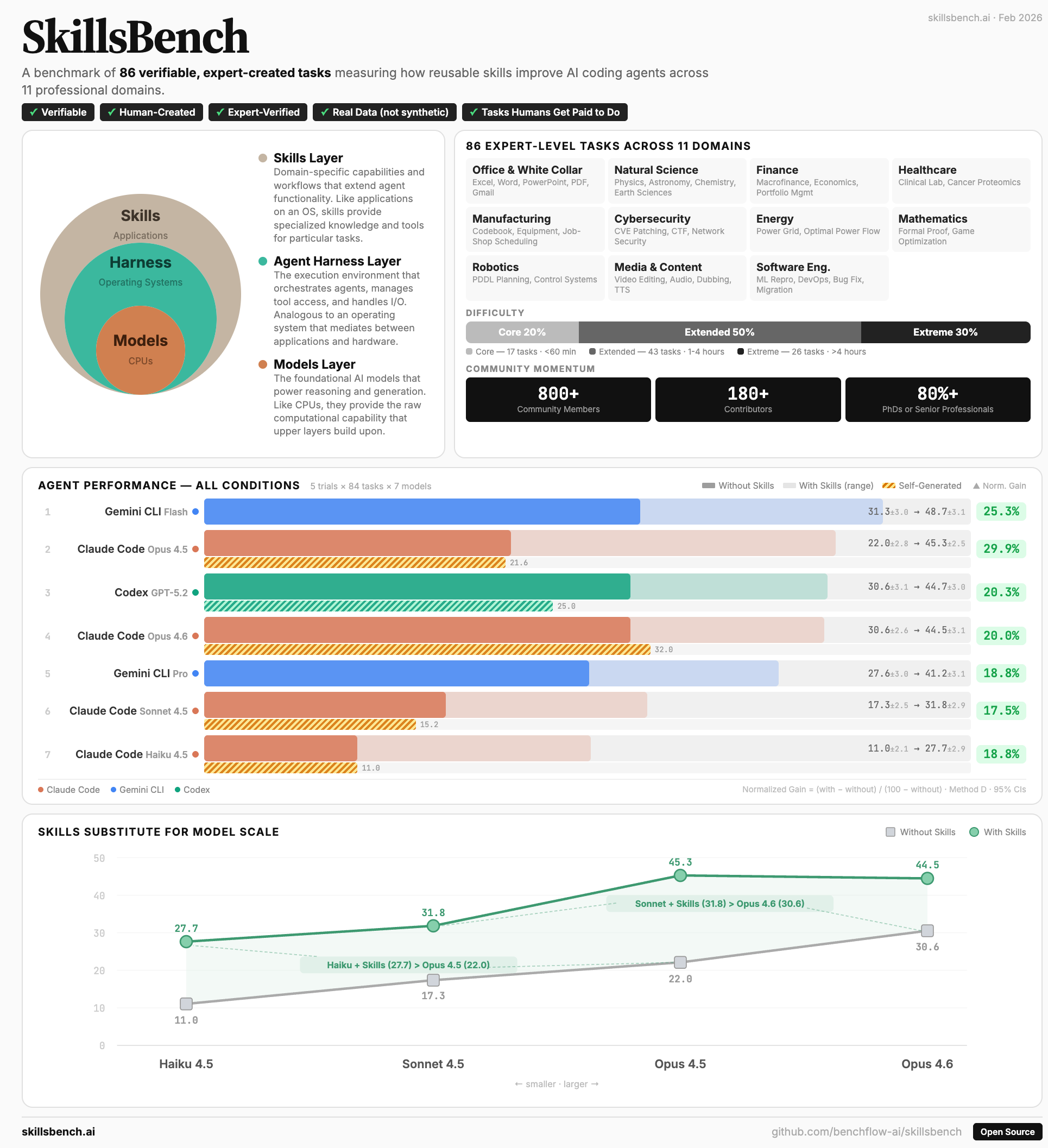 arXiv 2026 · Agent Skills · 1.1k stars
arXiv 2026 · Agent Skills · 1.1k stars